TLDR: avoid vague links like ‘Learn more’. Users scan pages and will often read links without the surrounding context. Links must set expectations that can be instantly met, and ideally should be terse in nature. They should be Specific, Sincere, Substantial and Succinct.
Prefer longer newsletters? You can subscribe to week11y, fortnight11y or even month11y updates! Every newsletter gets the same content; it is your choice to have short, regular emails or longer, less frequent ones. Curated with ♥ by developer @ChrisBAshton.
TLDR: engineers at Stripe examine the WCAG 2.0 minimum contrast ratio for text and how they arrived at their new accessible colour palette. It goes into great detail on how colour is represented on computer screens and how humans perceive colour, before describing the tool they’ve built to visualise perceptual contrast to help them to arrive at the right choice. Unfortunately there’s no link to the tool itself, nor to its code.
Prefer longer newsletters? You can subscribe to week11y, fortnight11y or even month11y updates! Every newsletter gets the same content; it is your choice to have short, regular emails or longer, less frequent ones. Curated with ♥ by developer @ChrisBAshton.
TLDR: Herbal Essences have built a voice-powered Alexa app that can help people find product recommendations for their hair type. Even more impressive is their funding of in-house experts to the Be My Eyes app; a free service that connects vision-impaired people with sighted volunteers through a live video call, to receive guidance while shopping or grooming. Finally, thanks to Herbal Essences‘ accessibility leader Sumaira Latif, tactile packaging will be introduced from January 2020 to help vision-impaired people distinguish between shampoos and conditioners.
Prefer longer newsletters? You can subscribe to week11y, fortnight11y or even month11y updates! Every newsletter gets the same content; it is your choice to have short, regular emails or longer, less frequent ones. Curated with ♥ by developer @ChrisBAshton.
TLDR: the GOV.UK Pay team upgraded to the latest version of GOV.UK Frontend to be fully compliant with the WCAG 2.1 AA standards, which includes a new accessible colour scheme.
Prefer longer newsletters? You can subscribe to week11y, fortnight11y or even month11y updates! Every newsletter gets the same content; it is your choice to have short, regular emails or longer, less frequent ones. Curated with ♥ by developer @ChrisBAshton.
TLDR: Disability rights lawyer Lainey Feingold discusses the aftermath of the Supreme Court’s decision not to hear the appeal case from Domino’s accessibility lawsuit ruling. She predicts Domino’s next step will be to argue that providing a phone line to customers fulfills its ADA obligations. She goes on to dismiss some kneejerk reactions to the ruling; for example, someone’s suggestion that “[next they’ll sue Domino’s for] not hiring blind delivery drivers” would, ironically, contravene the ADA for being a “direct threat to the health or safety of others”.
Background: Blind person in the USA sues Domino’s after being unable to order a custom pizza from its website or app. The Ninth Circuit Court ruled that the “alleged inaccessibility [of the website and app] impedes access to the goods and services of its physical pizza franchises” and thus violates the Americans with Disabilities Act (ADA). Domino’s petitioned to the Supreme Court, who on the 7th October declined to hear the case, leaving the ruling in place. Domino’s now intends to present their case to the trial court.
Prefer longer newsletters? You can subscribe to week11y, fortnight11y or even month11y updates! Every newsletter gets the same content; it is your choice to have short, regular emails or longer, less frequent ones. Curated with ♥ by developer @ChrisBAshton.
Disability rights lawyer Lainey Feingold discusses the aftermath of the Supreme Court’s decision not to hear the appeal case from Domino’s accessibility lawsuit ruling. She predicts Domino’s next step will be to argue that providing a phone line to customers fulfills its ADA obligations. She goes on to dismiss some kneejerk reactions to the ruling; for example, someone’s suggestion that “[next they’ll sue Domino’s for] not hiring blind delivery drivers” would, ironically, contravene the ADA for being a “direct threat to the health or safety of others”.
Background: Blind person in the USA sues Domino’s after being unable to order a custom pizza from its website or app. The Ninth Circuit Court ruled that the “alleged inaccessibility [of the website and app] impedes access to the goods and services of its physical pizza franchises” and thus violates the Americans with Disabilities Act (ADA). Domino’s petitioned to the Supreme Court, who on the 7th October declined to hear the case, leaving the ruling in place. Domino’s now intends to present their case to the trial court.
The GOV.UK Pay team upgraded to the latest version of GOV.UK Frontend to be fully compliant with the WCAG 2.1 AA standards, which includes a new accessible colour scheme.
Herbal Essences have built a voice-powered Alexa app that can help people find product recommendations for their hair type. Even more impressive is their funding of in-house experts to the Be My Eyes app; a free service that connects vision-impaired people with sighted volunteers through a live video call, to receive guidance while shopping or grooming. Finally, thanks to Herbal Essences‘ accessibility leader Sumaira Latif, tactile packaging will be introduced from January 2020 to help vision-impaired people distinguish between shampoos and conditioners.
Engineers at Stripe examine the WCAG 2.0 minimum contrast ratio for text and how they arrived at their new accessible colour palette. It goes into great detail on how colour is represented on computer screens and how humans perceive colour, before describing the tool they’ve built to visualise perceptual contrast to help them to arrive at the right choice. Unfortunately there’s no link to the tool itself, nor to its code.
Avoid vague links like ‘Learn more’. Users scan pages and will often read links without the surrounding context. Links must set expectations that can be instantly met, and ideally should be terse in nature. They should be Specific, Sincere, Substantial and Succinct.
Did you know that you can subscribe to dai11y, week11y, fortnight11y or month11y updates! Every newsletter gets the same content; it is your choice to have short, regular emails or longer, less frequent ones. Curated with ♥ by developer @ChrisBAshton.
It’s standard practice to set a Cache-Control: max-age=31536000 on assets which are expected not to change, such as images.
This header instructs the browser to cache the asset for 31536000 seconds, which is one year. Which raises two questions for me:
Why a year? Why not ten years, or six months?
Do we actually expect browsers to cache this asset for a year?
Let’s find out.
Why a year?
The short answer is, the protocol doesn’t allow any value longer than a year. In the absence of a “cache this asset forever” header, a year is the longest possible time we can cache for.
The RFC actually says the following, which I find phrased quite vaguely:
To mark a response as “never expires,” an origin server sends an
Expires date approximately one year from the time the response is
sent. HTTP/1.1 servers SHOULD NOT send Expires dates more than one
year in the future.
The header is open to interpretation – a 1 year cache could mean “this asset expires in a year, at which point you should fetch a fresh copy from the server”. Or it could mean “this asset never expires, so don’t ever bother downloading this file again”. Reading the RFC I suppose it should mean the latter, but I don’t think this is commonly implemented in the industry and most people (and systems) will take “max age 1 year” at face value.
There is no explicit Cache-Control: cache-forever option. But everyone seems ok with this because a year is basically forever in the land of the internet. Well, everyone except me – it bothers me that we have no explicit way of communicating our intention! Setting an arbitrarily long max-age feels hacky, and I wish we had a dedicated header value that explained it better.
The closest thing I can find that fits the bill is the Cache-Control: immutable extension. This tells the browser that the asset will not change for the duration of its validity. In other words, if you have an image with a 3 month cache, it’s pointless fetching it again from the server because it won’t have changed, so just serve it from the cache.
You’d be forgiven for thinking that the max-age value would have done that anyway. I’d have thought that if an asset has, say, a max-age: 60, then the fact that it says it’s cacheable for a minute should therefore mean it always fetches from the cache until the asset has expired.
However, if the user has reloaded the page by explicitly clicking the ‘refresh’ button, the browser will often make requests to the server ‘just in case’ to see if the file has changed, even if the local asset in the cache hasn’t expired. In these cases, the amount of data transferred is minimal; the server returns a 304 Not Modified response and thus the browser downloads only a few bytes per asset rather than re-downloading the assets in their entirety. But it’s frustrating that the browser makes these requests if you’ve already explicitly stated that the assets will not change for a year.
That’s where immutable comes in – assets served with the immutable extension will not be re-validated against the server even if the user clicks ‘refresh’ in their browser. immutable is no replacement for (and should be used ‘in conjunction with’) max-age, and it’s worth noting that browser support is currently somewhat limited:
Cache-Control: max-age: 31536000, immutable
So in terms of a “cache forever” header, it looks like the example above is the best option we have for now. It essentially means: “cache for a year – except, don’t cache for a year but actually treat this as ‘never expires’, according to the RFC – and it’s immutable, so don’t go asking the server about this asset ever again. Yes, even if you explicitly refresh the page”.
As an aside: before HTTP/1.1, we did used to set a cache value of longer than one year using the Expires header, which takes a timestamp of expiry rather than a relative time. It was common practice to set an expiry date “to the maximum future date your web server will allow“, which was Sun, 17-Jan-2038 19:14:07 GMT (the maximum value supported by the 32 bit Unix time/date format). This is longer than a year, but still not quite ‘forever’. Anyway, we now use Cache-Control as it’s generally more flexible – Expires should only be used as a fallback for older browsers.
So, do browsers actually cache this asset for a year?
Browsers have a limited amount of cache space they can use. As users browse the web, the cache fills up with more and more content until it’s full, at which point older things start getting dropped from the cache (in what’s known as a “least recently used”, or LRU, cache replacement strategy).
So in order for an asset to stay in a user’s cache for an entire year, we’d need a large enough cache to cope with a year’s worth of internet browsing. Most people don’t even have a big enough hard drive that would be required to accommodate the 1020 GB annual internet use per per household. But even assuming an infinitely large hard drive, most browsers cap their cache to around 100 MB – 200 MB (based on personal experience – citation needed!).
Therefore, it’s highly unlikely a user would see an image on a site and then revisit the site a year later and have the same image served from their cache. In fact, a Facebook study found that in 42% of cases, a cache is no more than 47 hours old.
If a browser is never reasonably expected to cache an asset for a year, why are web developers collectively peddling the lie that they do?
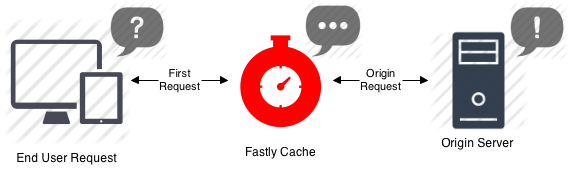
The answer is that the 1 year cache isn’t really expected to apply to the browser itself, but is expected to apply to any intermediate proxies employed by CDNs (Content Delivery Networks) such as Akamai, Varnish, Google’s AMP cache, etc.
CDNs are designed to deal with extremely high levels of traffic, across multiple regions, and thus reduce the load on the origin server. They essentially act as a middle layer between the user and your original server.
When a request is made for an asset via the CDN, the CDN will serve it from its own cache if it exists, otherwise it will fetch the asset from the origin server and then store it in its own cache, to be stored for as long as the Cache-Control header is set. So in this case, the CDN would cache the asset for a year, as it isn’t subject to the same cache restrictions as the browser is.
This can make a big difference to the performance of your server. Think about it.
Browsers are ‘forgetful’ (small cache, regularly cleared) and have major FOMO (a refresh will make additional requests to your server to re-verify that the cached assets haven’t changed), so even if you only have return visitors, your server still has to re-deliver those same assets (or at least a 304 Not Changed response).
If we employ a CDN as middleware, the request for those assets only happens once – by the CDN itself – and all those subsequent repeat requests can be handled directly by the CDN.
And because we can purge CDN caches (something we’re unable to do with users’ browser caches), we can even specify different cache values for the CDN and the browser, to balance the best of both worlds. A shorter cache on the client guarantees their asset doesn’t stay stale for too long if we update our asset, and a longer cache on the CDN minimises revalidation requests on your server.
Cache-Control: s-maxage=31536000, max-age=86400
The above value instructs the CDN to cache your asset for a year, but the browser to cache the asset for a day. If you update your asset, you can instruct your CDN to purge its cache and to grab a fresh copy.
Are we missing a trick here?
Consider the current situation – a one year cache on CDNs, fetching a ‘fresh’ version from the origin server a year later, even if the asset never changes. (And, in practice, anything that’s set to cache for a year is not going to change).
Even with a CDN in place, we need to hold onto the original asset on the origin server so that when the CDN revalidates in a year’s time, there is still an asset to replace their cached version with. If the asset no longer exists on the origin server, then it is generally removed from the CDN too.
This means that we need to hold on to all of our assets, and keep our server running, even though we’re paying for a CDN which is handling most of the traffic to our site.
What if we had a Cache-Control: cache-forever option?
With our assets cached by the CDN, we could remove them from our origin server. Heck, within reason, we could even shut down our origin server altogether – let all the traffic be handled by our CDN. Without the need to revalidate in a year’s time, we can cut costs (and help the environment) by shutting down unneeded instances and deleting unneeded assets.
It seems that a 1 year cache is basically shorthand for “cache this asset for, like, ever” – so why don’t we have a value that actually shows that intent?
Food for thought.
Summary
We set a 1 year cache because that’s the largest value allowed by the protocol.
Browsers don’t store things in their cache for a year, but CDNs do.
The world would be a better (and more understandable) place if we had an explicit cache-forever option. But we don’t.
What will the Web of tomorrow look like? With an increasing array of publishing platforms to think about, from AMP to Apple News to Facebook Instant Articles, the very principles of the Web are being tested. A URI – Unique Resource Identifier – is no longer particularly unique when it’s being duplicated in many forms.
In this talk I will explore the implications of this technological landscape: the pressure on publishers to get their content out to where audiences now live; the siloing effect of multi-platform delivery (audiences no longer need to leave their bubble to get content). Mostly, I will describe the technological challenges associated with managing this increased complexity, and how we have dealt with the challenges in the Visual Journalism team at the BBC.
We’ve developed an innovative “wrapper pattern” which isolates our code from the environment in which it is shipped, so that we can write the code once and deploy it to multiple platforms, avoiding handling edge cases in each platform and leaving this complexity to the abstraction layer.
The technical solution requires collaboration with multiple teams, as each platform delivery team has to adopt the naming convention we’ve used for our content and how it is represented in the CMS.
It’s by no means a silver bullet, and even with the wrapper abstraction we have to deal with the edge cases of certain platforms under certain conditions.
I will explain the thinking behind the wrapper pattern, how we’ve implemented it, and how we tackle problems that we continue to face with it.
I attended DeltaVConf a couple of weeks ago, and there was a lot of talk about preloading fonts to improve web performance. Without preloading fonts, the browser fetches HTML – which in turn downloads CSS – and then parses the CSS, and only much later do the associated font files get downloaded when it looks like they’re going to be applied to elements in the DOM.
With preload, the fonts are fetched much earlier on (before CSS is parsed), saving significant time on the first render (as much as a second in a lot of cases).
It looked like a quick win that I could apply to my Google web fonts.
A Google Font link is a stylesheet link
Now, I’ve seen a lot of articles showing how to preload fonts using link rel="preload", but they all provide examples for local font files rather than Google fonts. Their examples look nice and easy:
Oddly, my fonts were still not being applied to my document, even though I could see the request being made to Google (this time with the correct Type: ‘style’).
It turns out preload serves as a hint to the browser to download the asset as soon as possible, as it will be needed later. But it doesn’t know when you’re going to need that asset – it’s just believing you when you’ll say you need it. For example, you may load that stylesheet in the head, or you may dynamically load the stylesheet using JavaScript.
Whilst preload downloads the asset, it doesn’t actually apply it, because it shouldn’t until you tell it to.
I therefore had to add my original stylesheet call back in:
This pre-fetches my stylesheet, and then immediately requests the stylesheet for applying as CSS. I now have my fonts again – woohoo!
But really, this has done nothing to boost the performance of my page – I’m not downloading the CSS any quicker than before, and the fonts themselves are still taking a while to download. This is because the fonts are external requests made by my call to googleapis.com. I can pre-load the googleapis.com stylesheet but that’s no guarantee it’ll download the fonts any quicker.
What I actually need to do is go and preload the font files, not the Google stylesheet. This is where things get a little messy.
Let’s look at third-party code!
I need to manually preload the external fonts that the Google stylesheet will download.
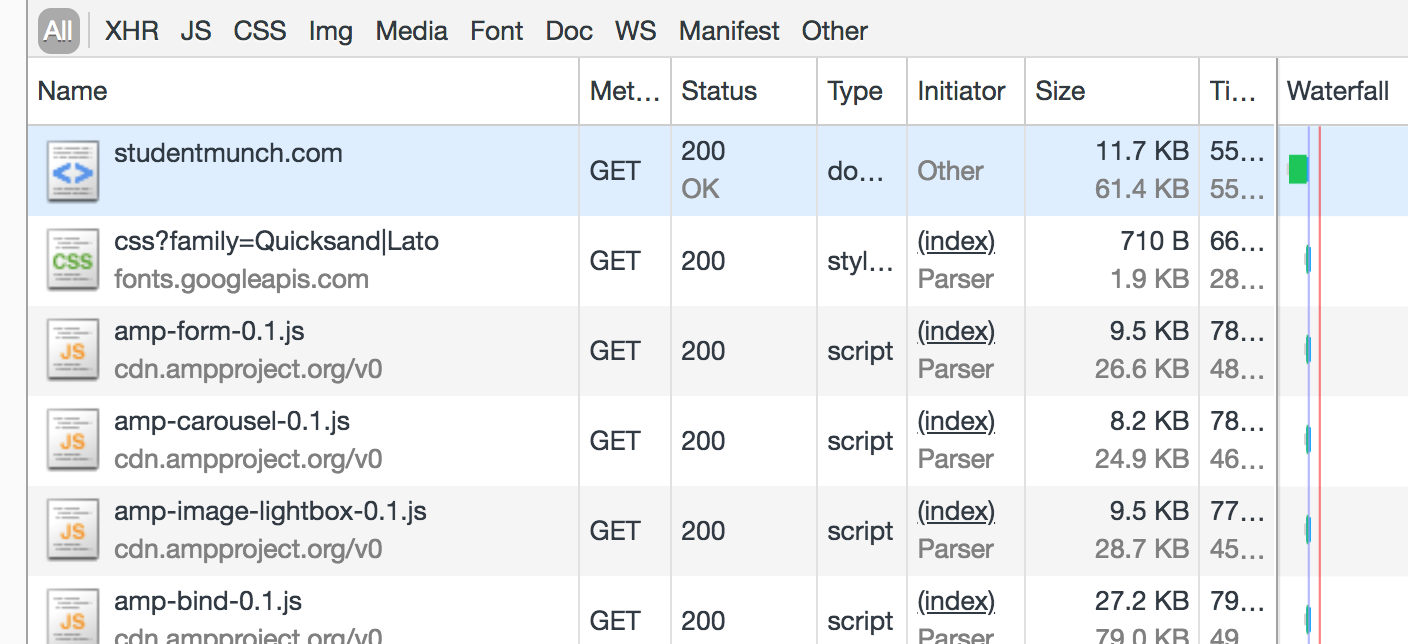
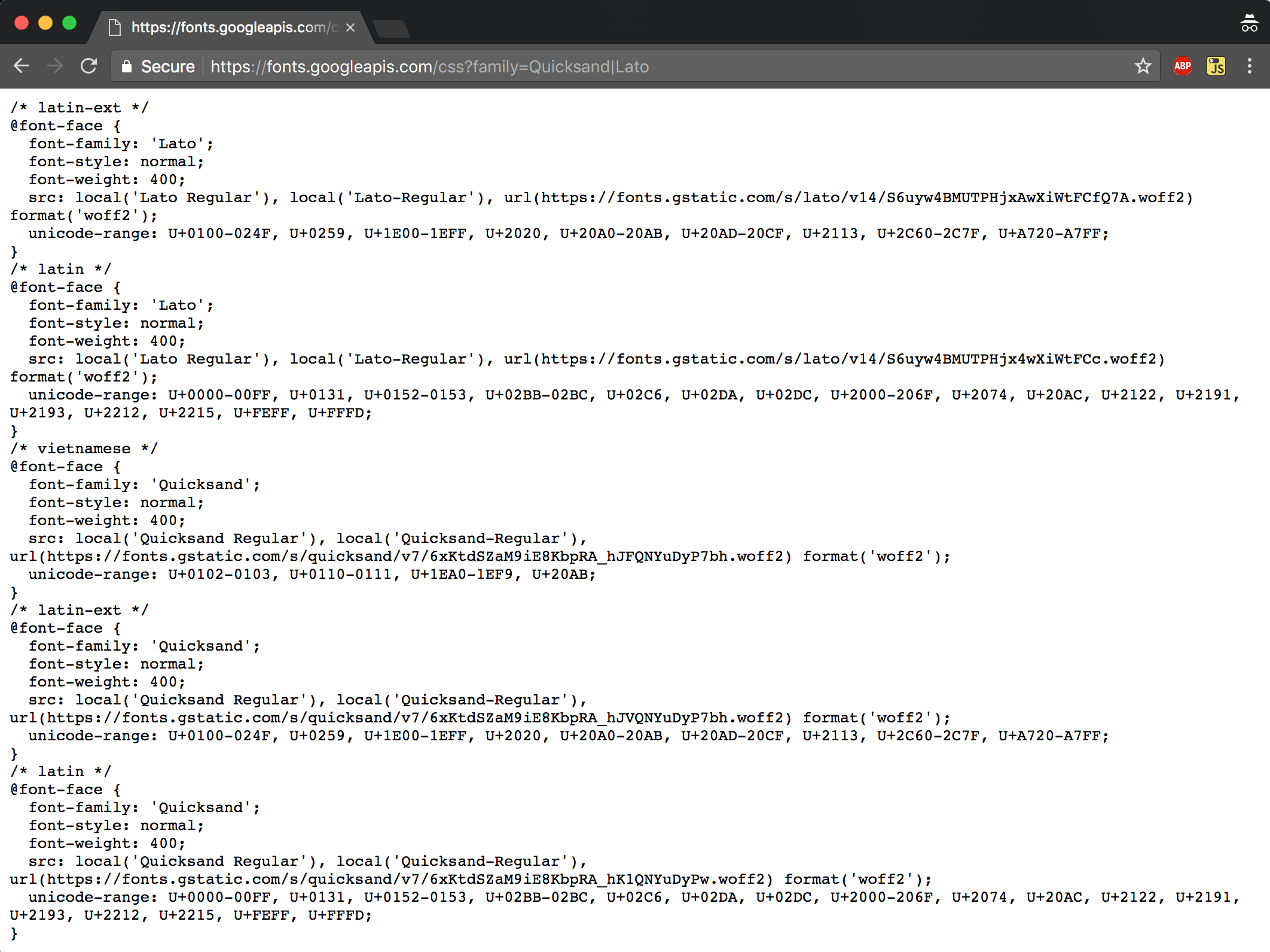
And to do that, I need to dig into the Google CSS file to see which fonts are needed.
This lists five different font files. I don’t need all these – I just need the latin font. I don’t use Vietnamese on my site.
I don’t need latin-ext fonts either: this stands for Latin Extended, and whilst Latin caters for Western European languages, Latin Extended supports Eastern European characters, for example Å, Ä, or Ö. I never need to use these on my site, so I’ll only preload the Latin character set from both fonts.
Notice the crossorigin attribute, which is required to preload assets that exist on another domain.
Another way of figuring out which font files you need is to check your Network tab. This has the handy advantage of explicitly showing you how much bloat you’re adding to your page in KB!
Preconnect
If you’re making a few round trips to a CDN to download assets, you can shave a few milliseconds off those requests by opening up a preconnection to the server. From w3.org, the preconnect resource hint initiates an early connection of DNS lookup, TCP handshake and optional TLS negotiation, saving subsequent requests from having to repeat those steps.
I added this resource hint just above my font requests:
We’ve optimised to the point of opening early requests to CDNs, digging into third-party CSS, cherry-picking external assets and then pre-fetching those dependencies manually. So, do we really need that original external stylesheet anymore?
We’ll still need to declare those @font-face styles somewhere on our site, but we can now choose to do this inline or in our own internal pre-fetched stylesheet, saving a round-trip HTTP request to the Google Fonts stylesheet.
I accomplish this by putting the @font-face declarations inline immediately below my preload resource hint:
As stated earlier, this is risky because fonts are regularly updated by Google and there is no guarantee that older fonts won’t be expired at some point in the future, killing performance on your site with failed requests while users only see your fallback fonts.
I elect to download the fonts myself later and preload locally hosted fonts, but for now let’s do some benchmarking.
Is it any faster?
It’s hard to tell, but I think – think – my site is up to 19% faster at rendering.
On a simulated slow 3G connection, my site originally had a First Meaningful paint of ~12.4 seconds. After preloading the fonts, I got this down to ~10.4 seconds.
I was pretty happy at this point, but then discovered Addy’s talk on YouTube and decided it was probably best that I make a local copy of font files rather than continue to use Google fonts at high risk of breaking.
Here is my final code
After downloading local copies of the fonts, this is my final code (I’m just showing ‘Quicksand’, for brevity):
Of course! Apart from the almost 20% improved rendering time, I feel more in control over the assets of my site and more informed as to which fonts are used where, how big they are, and when they should be loading. It was a useful chance to review my practices.
For example, I realised that at first, I was pulling in these fonts:
This defines font-faces for multiple font-weights and italic style – even though I only use the ‘normal’ style of font.
Whilst these extra font faces aren’t downloaded unless your CSS depends upon it, the CSS file itself is a little larger, at 5.7KB rather than 1.9KB – so even without the preload optimisation, this exercise was worth doing!
And of course, I removed the dependency on the Google font CDN altogether, so that 1.9KB of CSS is now just 728 bytes of inline CSS (minified), with just the latin fonts downloaded.
Your WordPress theme might have multiple loops in the page. For example, there may be a ‘Featured’ section at the top of your homepage, and a ‘Recent Posts’ section below that.
These are separate loops, but could contain the same post. For example, your most recent post might also be in the Featured category.
You only want the post to appear once. How do you manage it?
Avoid showing duplicate WordPress posts
The answer is surprisingly simple. Put the following in your functions.php.
<?php
add_filter('post_link', 'track_displayed_posts');
add_action('pre_get_posts','remove_already_displayed_posts');
$displayed_posts = [];
function track_displayed_posts($url) {
global $displayed_posts;
$displayed_posts[] = get_the_ID();
return $url; // don't mess with the url
}
function remove_already_displayed_posts($query) {
global $displayed_posts;
$query->set('post__not_in', $displayed_posts);
}
We only want to hide posts which have been displayed already – so we hook into the post_link() function call and make a note of the post we’re displaying.
We then want to hook into any new WordPress query to tell the query to not include any of the posts we’ve already seen. We do this by hooking into the pre_get_posts function and passing it our list of already-displayed posts.
And if you find this plugin or this code snippet useful, please comment below and let me know!
Want some more great WordPress tools? Check out my other plugin: Secretary.
This post was updated in December 2019 to refer to the new way of detecting which posts have been displayed, using post_link rather than the_title as a hook, as post previews don’t always use the_title (they may be thumbnail only) but they DO always have a link.