It’s standard practice to set a Cache-Control: max-age=31536000 on assets which are expected not to change, such as images.
This header instructs the browser to cache the asset for 31536000 seconds, which is one year. Which raises two questions for me:
- Why a year? Why not ten years, or six months?
- Do we actually expect browsers to cache this asset for a year?
Let’s find out.
Why a year?
The short answer is, the protocol doesn’t allow any value longer than a year. In the absence of a “cache this asset forever” header, a year is the longest possible time we can cache for.
The RFC actually says the following, which I find phrased quite vaguely:
To mark a response as “never expires,” an origin server sends an
Expires date approximately one year from the time the response is
sent. HTTP/1.1 servers SHOULD NOT send Expires dates more than one
year in the future.
The header is open to interpretation – a 1 year cache could mean “this asset expires in a year, at which point you should fetch a fresh copy from the server”. Or it could mean “this asset never expires, so don’t ever bother downloading this file again”. Reading the RFC I suppose it should mean the latter, but I don’t think this is commonly implemented in the industry and most people (and systems) will take “max age 1 year” at face value.
There is no explicit Cache-Control: cache-forever option. But everyone seems ok with this because a year is basically forever in the land of the internet. Well, everyone except me – it bothers me that we have no explicit way of communicating our intention! Setting an arbitrarily long max-age feels hacky, and I wish we had a dedicated header value that explained it better.
The closest thing I can find that fits the bill is the Cache-Control: immutable extension. This tells the browser that the asset will not change for the duration of its validity. In other words, if you have an image with a 3 month cache, it’s pointless fetching it again from the server because it won’t have changed, so just serve it from the cache.
You’d be forgiven for thinking that the max-age value would have done that anyway. I’d have thought that if an asset has, say, a max-age: 60, then the fact that it says it’s cacheable for a minute should therefore mean it always fetches from the cache until the asset has expired.
However, if the user has reloaded the page by explicitly clicking the ‘refresh’ button, the browser will often make requests to the server ‘just in case’ to see if the file has changed, even if the local asset in the cache hasn’t expired. In these cases, the amount of data transferred is minimal; the server returns a 304 Not Modified response and thus the browser downloads only a few bytes per asset rather than re-downloading the assets in their entirety. But it’s frustrating that the browser makes these requests if you’ve already explicitly stated that the assets will not change for a year.
That’s where immutable comes in – assets served with the immutable extension will not be re-validated against the server even if the user clicks ‘refresh’ in their browser. immutable is no replacement for (and should be used ‘in conjunction with’) max-age, and it’s worth noting that browser support is currently somewhat limited:
Cache-Control: max-age: 31536000, immutable
So in terms of a “cache forever” header, it looks like the example above is the best option we have for now. It essentially means: “cache for a year – except, don’t cache for a year but actually treat this as ‘never expires’, according to the RFC – and it’s immutable, so don’t go asking the server about this asset ever again. Yes, even if you explicitly refresh the page”.
As an aside: before HTTP/1.1, we did used to set a cache value of longer than one year using the Expires header, which takes a timestamp of expiry rather than a relative time. It was common practice to set an expiry date “to the maximum future date your web server will allow“, which was Sun, 17-Jan-2038 19:14:07 GMT (the maximum value supported by the 32 bit Unix time/date format). This is longer than a year, but still not quite ‘forever’. Anyway, we now use Cache-Control as it’s generally more flexible – Expires should only be used as a fallback for older browsers.
So, do browsers actually cache this asset for a year?
Browsers have a limited amount of cache space they can use. As users browse the web, the cache fills up with more and more content until it’s full, at which point older things start getting dropped from the cache (in what’s known as a “least recently used”, or LRU, cache replacement strategy).
So in order for an asset to stay in a user’s cache for an entire year, we’d need a large enough cache to cope with a year’s worth of internet browsing. Most people don’t even have a big enough hard drive that would be required to accommodate the 1020 GB annual internet use per per household. But even assuming an infinitely large hard drive, most browsers cap their cache to around 100 MB – 200 MB (based on personal experience – citation needed!).
Therefore, it’s highly unlikely a user would see an image on a site and then revisit the site a year later and have the same image served from their cache. In fact, a Facebook study found that in 42% of cases, a cache is no more than 47 hours old.
If a browser is never reasonably expected to cache an asset for a year, why are web developers collectively peddling the lie that they do?
The answer is that the 1 year cache isn’t really expected to apply to the browser itself, but is expected to apply to any intermediate proxies employed by CDNs (Content Delivery Networks) such as Akamai, Varnish, Google’s AMP cache, etc.
CDNs are designed to deal with extremely high levels of traffic, across multiple regions, and thus reduce the load on the origin server. They essentially act as a middle layer between the user and your original server.
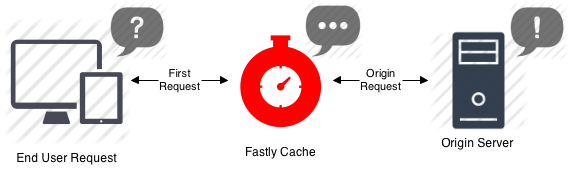
When a request is made for an asset via the CDN, the CDN will serve it from its own cache if it exists, otherwise it will fetch the asset from the origin server and then store it in its own cache, to be stored for as long as the Cache-Control header is set. So in this case, the CDN would cache the asset for a year, as it isn’t subject to the same cache restrictions as the browser is.
This can make a big difference to the performance of your server. Think about it.
Browsers are ‘forgetful’ (small cache, regularly cleared) and have major FOMO (a refresh will make additional requests to your server to re-verify that the cached assets haven’t changed), so even if you only have return visitors, your server still has to re-deliver those same assets (or at least a 304 Not Changed response).
If we employ a CDN as middleware, the request for those assets only happens once – by the CDN itself – and all those subsequent repeat requests can be handled directly by the CDN.
And because we can purge CDN caches (something we’re unable to do with users’ browser caches), we can even specify different cache values for the CDN and the browser, to balance the best of both worlds. A shorter cache on the client guarantees their asset doesn’t stay stale for too long if we update our asset, and a longer cache on the CDN minimises revalidation requests on your server.
Cache-Control: s-maxage=31536000, max-age=86400
The above value instructs the CDN to cache your asset for a year, but the browser to cache the asset for a day. If you update your asset, you can instruct your CDN to purge its cache and to grab a fresh copy.
Are we missing a trick here?
Consider the current situation – a one year cache on CDNs, fetching a ‘fresh’ version from the origin server a year later, even if the asset never changes. (And, in practice, anything that’s set to cache for a year is not going to change).
Even with a CDN in place, we need to hold onto the original asset on the origin server so that when the CDN revalidates in a year’s time, there is still an asset to replace their cached version with. If the asset no longer exists on the origin server, then it is generally removed from the CDN too.
This means that we need to hold on to all of our assets, and keep our server running, even though we’re paying for a CDN which is handling most of the traffic to our site.
What if we had a Cache-Control: cache-forever option?
With our assets cached by the CDN, we could remove them from our origin server. Heck, within reason, we could even shut down our origin server altogether – let all the traffic be handled by our CDN. Without the need to revalidate in a year’s time, we can cut costs (and help the environment) by shutting down unneeded instances and deleting unneeded assets.
It seems that a 1 year cache is basically shorthand for “cache this asset for, like, ever” – so why don’t we have a value that actually shows that intent?
Food for thought.
Summary
- We set a 1 year cache because that’s the largest value allowed by the protocol.
- Browsers don’t store things in their cache for a year, but CDNs do.
- The world would be a better (and more understandable) place if we had an explicit
cache-foreveroption. But we don’t.