Building on the shoulders of giants
There is definitely a trade-off to be considered when using existing software. On the one hand, there is a learning curve: it takes a long time to find your way around the codebase and learn the purpose of each file.
In addition to a big learning curve, it can be difficult to place the blame if you encounter a bug:
- Is it a bug in the open source software?
- Is it a bug because of the way we’re using the open source software (in a manner it was not intended for)?
- Is it a bug that we introduced in our code modifications?
In comparison, it is tempting to build software from scratch because of the lower learning curve; the project is developed incrementally and as a developer you gradually introduce yourself to new concepts and files, perhaps arriving at a project of a similar size to existing open source projects but having eased your way into the learning process.
Building from scratch is certainly more time-consuming. If a software system takes 100 hours to build from scratch, it is better to spend 10 hours learning an existing system and modifying it for your own uses. It is also likely to be better engineered, since it is likely to have had more developer hours invested in refining it.
Early on in my Major Project investigations I discovered Emcod; “an innovative project which aims to broaden Access to justice through use of Online dispute resolution”. It is an open-source tool designed for a LAMP server (Apache, MySQL, PHP).
I had hoped to use it as a basis for my Major Project, but on closer inspection this might not be a good idea.
- It’s unclear what the code actually does! According to the website, Emcod “allows providers of Online dispute resolution to measure the costs and quality of their services”. How it does this is unclear, but it does suggest that the software does not actually provide the online dispute resolution process itself.
- The website is poor. Though there are some installation instructions and a download to the source code, there are two items of text that look like links (and presumably were intended to become links one day) – these are ‘User manual’ and ‘Watch video’.
- Due to the poor website and general lack of information, it’s hard to find out exactly when the code was released, but the download link (http://www.emcod.net/wp-content/uploads/2012/01/emcod.tar.gz) suggests January 2012. This is a stagnant codebase – it has not been updated since then.
In spite of any good documentation or description, I thought it would be a worthy investment of time to at least try and get the software up and running (as I have access to my own cloud LAMP server) to see if it would meet my needs.
An alternative open source framework to begin with is HumHub – a “Flexible, Open Source Social Network Kit”. ODR platforms aren’t social networks, but there are aspects of social activity such as Case timelines, private communication, “groups” of Agents in the same network (their Company), and so on. Also, additional functionality such as file upload facilities and user authorisation would be useful modules to reuse.
One of the pluses of HumHub, according to its website, is its flexibility. “With a powerful module system you can extend HumHub by using third party tools, writing your own or connect existing software”, so it should be possible to plug in all manner of functionality.
Emcod
Emcod was nice and easy to install:
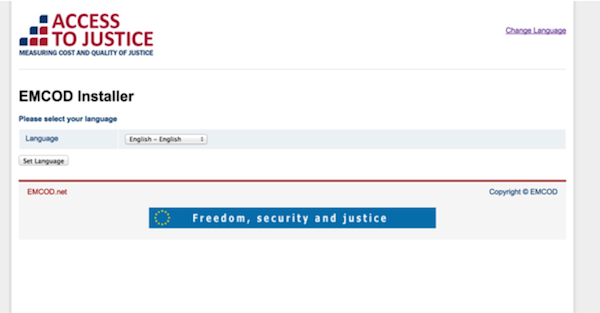
And it handled login nicely:
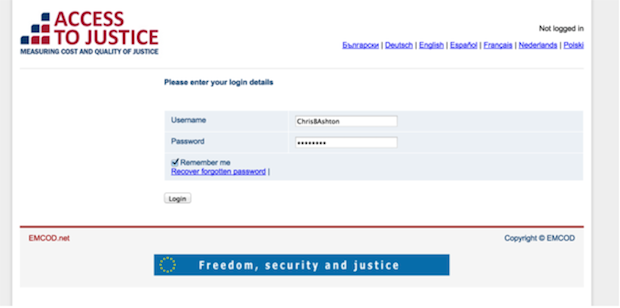
But, sure enough, this didn’t look like online dispute resolution software.
It’s madness that I had to install the software to actually find out what it does. It was a long shot, but unfortunately this was not a suitable framework to build upon.
HumHub
Again, this was nice and easy to install. Below is a screenshot after having logged in and set up a profile.
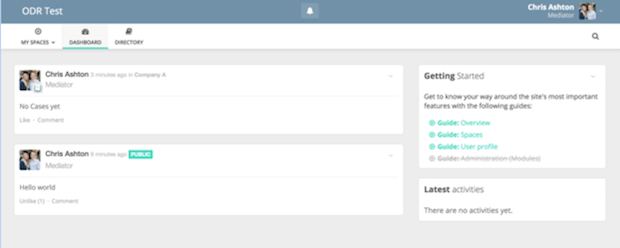
HumHub has a concept of “spaces”, effectively groups where there is a central board everyone in the space can write to. This could be the basic underpinning of Case communication, if I can programmatically generate spaces.
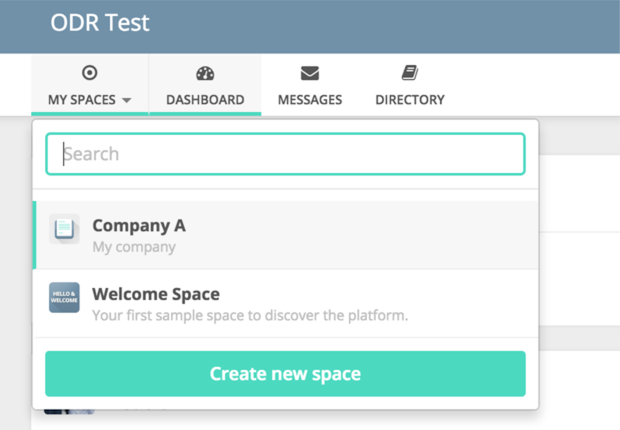
HumHub has a modular system such that you can install and uninstall modules freely, and develop your own. I may be able to hook into rendering functions and so on, and add disputes as a function.

There’s no getting around the fact that HumHub was not intended to be an ODR platform. But what it DOES do for us is handle authorisation, authentication, profile management, and so on, so could be worth considering further.
Its repository is very active, and well documented, though there is a large backlog of issues.
I need to balance whether or not it is worth pursuing HumHub.
HumHub – Advantages
- Actively maintained
- Modular support
- Built-in functionality that we need, including:
- Registration
- Login
- Notifications
- Concept of a central “space” for communication
- Attractive UI
HumHub – Disadvantages
- A lot needs to be changed – e.g. “liking” evidence is not appropriate!
- Although developed modularly, it may not provide enough hooks for all the functionality I’ll need to develop
- Large codebase to get to grips with, therefore a large learning curve
- No getting away from the fact that the purpose of this software is fundamentally different to ODR platforms.
- We don’t want to be locked into third-party consumerist bubble.
- Release under the AGPL license restricts what we can do with our codebase (i.e. we cannot stay closed-source).
Perhaps I don’t need a full system to base my project on. Perhaps I can delegate parts of my system to different libraries, taking care to write accessor classes using the Decorator pattern, giving me the freedom to swap out for different modules if necessary.
An early candidate worth considering is the Huge library, which despite its name is not an overly large and complex codebase, and could be a basis for my user registration/authentication/login functionality.