I’ve been thinking about the commercial viability of my project.
As a result of using the Fat-Free Framework, my project is forced to adhere to the terms of the GPLv3 license, which stipulates that if I distribute my software I must make the source code easily available. In theory, this shouldn’t force me to go open source. As my project is web-based, I am within my rights to deploy my code to a server, and any users of a website that uses that code do not have the right to access the source code, since I’m not deploying the program itself to them: only the results of the program. The AGPL license would be a different story, as it closes that loophole.
Nevertheless, I’ve chosen to make my project open source. Why? Well, partly because GitHub charges for private repositories, and all of the CI tools that I’m using in my project (Travis, CodeClimate, Gemnasium) are free for open-source projects, but charge money for private repositories. In addition to all this, I want people to be able to follow my progress. I want something I can show future employers. I also found it very useful to be able to show my supervisor my feature files so that they could be double-checked and signed off.
All these reasons led to me open-sourcing my project: but does that hinder its commercial viability? One’s instinct is to say “yes” – if people can download, modify, run and re-distribute your software for free, why would they ever want to pay for it? I believe my project does hold commercial promise, and the reason came to me while I was trying to plan out what I would say in my Mid-Project Demonstration, which is happening this time next week.
Where is the cool stuff?
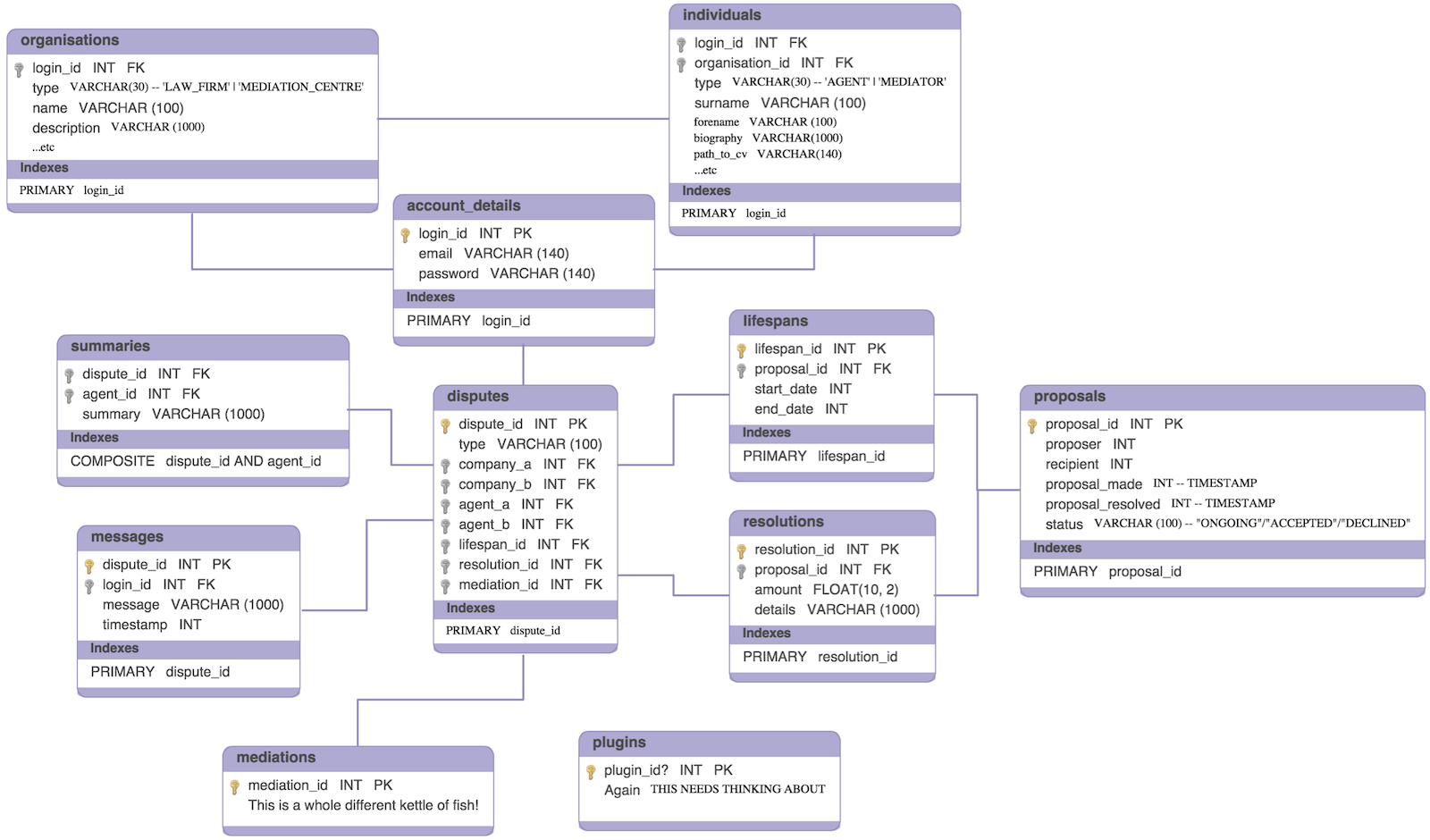
I feel I have to justify the amount of time spent building the core ODR platform. After all, the exciting bit about my project, surely, is all about the maritime collision logic; the AI and the neural networks and the natural language processing that form the virtual court simulation and replace the physical court. That’s some pretty awesome stuff right there.
Though the maritime collision logic is seemingly the exciting, ground-breaking stuff, there’s also been a heavy emphasis on keeping the underlying system as abstract as possible, so that any module of business logic can be plugged into the system. And that, ladies and gentlemen, is where the truly exciting stuff is.
The core ODR platform is a large, extensible, robust and skilfully constructed framework. It needs to be, if developers are to have any confidence in building plugins for it. After completing the core platform, I expect to not have all the time in the world to work on the maritime collision module. I hope that, through the module, I can at least develop a plausible promise as to what the system is capable of. The maritime module is a prototype, a placeholder… something that other developers can spend a lot more time expanding upon in the future. The real meat of this project is in the underlying platform.
The analogy I’m hoping to use on Tuesday is this: the ODR platform is like WordPress. The Maritime Collision module is like a WordPress plugin. The former is, by necessity, a huge, well-tested framework which has had contributions from hundreds of developers. The latter could be as large in scope as the former, or it could be a one-script plugin that scratches a lone developer’s personal itch. Both can be developed independently of one another.
Investigating the WordPress pricing model
I realised that my project could learn many lessons from WordPress. Both projects do completely different things, but I can utilise and copy certain things like how WordPress fires events that plugins can be hooked into, and how it allows site administrators to easily install, upgrade and uninstall plugins directly through the admin dashboard provided. But going beyond the software level, I can also learn lessons from how WordPress makes money, and why they continue to do what they do.
With all the goodwill in the world, WordPress would not continue to be developed if money wasn’t being made somewhere. So where is it made? WordPress itself is free to download and install on any server as you wish. You can even save yourself the effort of doing that, and create your own WordPress subdomain directly through wordpress.com, at no cost.
The truth is, there are a lot of companies making a lot of money off the back of WordPress, and I’m sure some of the WordPress contributors are getting in on the action themselves. Developers can create plugins and themes, and though most of these are free, many of them are not… and some of them are really rather expensive.
WordPress is covered by the GPLv2 license, which is similar to the license covering my project. The genius thing is, WordPress plugins and themes are not confined to the terms of that license, as they are self-contained units of work that “just happen” to slot into the core WordPress platform and extend aesthetics or functionality. They are not modifications of the platform itself. This means that they can stay closed source, and therefore give people a reason to pay for them.
How this can be applied to my project
I think that keeping my ODR platform open-source is a smart move. Anyone is free to download the project, install it on their own server, and even start charging money for their online dispute resolution services. I think it’s also a good idea to make the maritime collision module free, and perhaps a handful of other dispute type modules too (such as divorce cases, unfair dismissal claims, etc), to make the system more useful and show people what is possible with the core platform.
If I were to continue with the project beyond university, my plan would be to develop even more dispute type modules: say, tenancy agreement breaches, slander, etc – and to charge money for these modules. Anyone would be able to set up a website with the core platform and some dispute types for free, but to rise above the competition and have the most comprehensive ODR system, they’d have to pay for additional modules. Think of it as The Sims’ expansion packs!
Building my brand
WordPress is as big as it is today because not only is it open source, but it is also a household name. It has built up a reputable brand and is now the market leader in blogging software. My ODR platform clearly needs an identity.
As a placeholder, I created a logo a couple of weeks ago, entitled “SmartResolution”. It seemed a fairly good and appropriate name: my platform offers online dispute resolutions, but in a smart way, i.e. input analysis and a heuristically-driven suggestion as to the outcome of the dispute.
Today I bought a domain name to help reinforce that branding: smartresolution.org. At the time of writing there is nothing to see yet, since I have no server – but I intend to set up AWS integration in the next couple of weeks so that I can easily and automatically deploy the latest version of my project to a cloud server, accessible through smartresolution.org.
I’m not expecting to make money from this (for a start there are other issues I haven’t discussed, such as my project technically being the property of Aberystwyth University), but at the very least it is an easy way to give my supervisor and stakeholders access to the beta version of my project. I’d like to develop my project as if it’s going somewhere, because if I don’t, it never will.
Other updates
That’s it for this blog post, but here’s a quick list of the project functionalities added since my last post:
- Lifespan negotiation and re-negotiation.
- Communication between agents within a dispute.
- Various refactorings, including using the state pattern to significantly tidy up my business logic.
- A one-step install script.
- Better overall tests and code structure.