Recently our first year computer science department had a lecture on IP Datagrams. While people were Facebooking and falling asleep around me, I paid attention. It’s definitely worth learning the science behind data transfer over the internet or we risk being locked in to a consumerist bubble, where we’ve all been trained to use obscolete products and protocols, no longer able to define our own.
Data transfer is fundamentally simple, but has its complications. I will relay to you the information I learned in the lecture. Only when you have an understanding of the current protocol for data transfer will I tell you my suggestion for its improvement. So, how do you send a file from a computer in London to a computer in Manchester?
Let’s say we have a small text file. The data from this file, made up of binary 1s and 0s, is stored in something called an IP Datagram, which travels with its IP Header. Amongst other things, the IP Header contains the source address and the destination address. These are IP addresses, 32 bits in length each (in Internet Protocol version 4).
The IP Datagram (containing the IP Header and the data) is sent from your computer to your router, via an ethernet cable or wireless connection. Your router has awareness of a number of nearby routers/exchanges. It will look at the destination address in the IP Header and decide which router or exchange is the most applicable to send the datagram to, in order to get closer to its destination. The same thing happens at the next router; checking the destination address and calculating which router to send the datagram to. This continues until, eventually, the datagram reaches its destination.
What happens if the data is too large to be carried across a subnetwork, a large video file for example? In cases like these, the datagram is fragmented. The data is split across multiple datagrams with almost identical IP Headers, which are then “linked up” upon reaching their destination. I say almost identical datagrams- there is a subtle difference in the IP Header, called the Fragment Offset, which keeps a record of where the fragment came in the original message. This ensures that the fragments of data are put back together in the correct order.
Let’s take a closer look at the IP Header. In addition to the source and destination address, the header stores a header checksum, which checks whether the information provided in the header was corrupted at any point on its journey between two routers. It does not protect the user’s data at all, it is only a validator for itself, the header. This does not bear much concern to my article, but it indicates that the IP Header can store lots of different information, which is fundamental to a couple of the concepts I am about to suggest.
With IP Datagrams being transferred from router to router all over the place, problems can arise. If one router thinks one route is best and another router disagrees, the datagram could be stuck in an infinite loop, never reaching its destination but using valuable network bandwith. The current solution to this problem is to use something called “Time To Live” (TTL).
When one router passes a datagram to another, that counts as one “hop”. The TTL concept is to allocate to datagrams a set number of hops before the datagram is considered lost and is discarded from the network. This value is typically around 30, but can go as high as 255. Consider the following example, which has a TTL of 3.
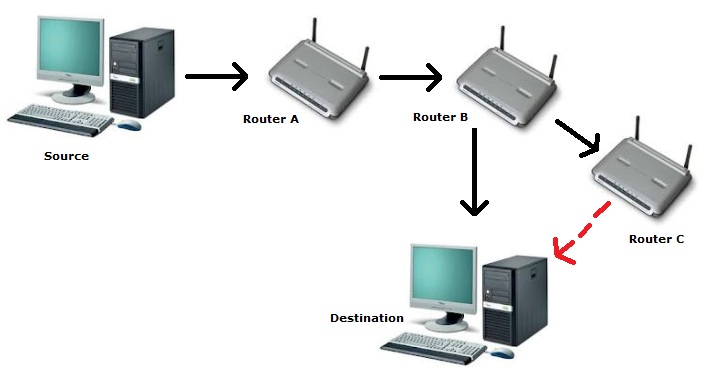
The datagram is passed from the source to Router A- this uses one hop. Router A sends the datagram to Router B, which uses another hop, bringing the total number of hops to two. If Router B now transfers the datagram to the destination, the transfer is completed successfully, as it has used 3 hops. If, however, it sends the datagram to Router C, which would then send the datagram to its destination, the datagram would be discarded. Why? Because going via that route would use 4 hops, but the datagram only has a TTL (Time To Live) of 3.
This is a good, working system, though it means that those building our network infrastructure have to think carefully. If somebody wanted to establish a connection between the North and South poles, this typically has to be done in less than 30 hops, which could prove difficult. Also, the further the data has to travel between routers, the more likely it is that the data will be corrupted. This is why, in my opinion, the TTL solution isn’t necessarily the ideal one- there should not be a limit on the number of routers used to transfer information.
My first idea is simple- rather than having a Time To Live, we keep track of the routers that have been passed through. The IP address of each router is stored cumulatively in the IP Header of the datagram. Quite simply, we do not allow the datagram to pass through the same router twice. I realise that this could potentially lead to some long, convoluted route being taken, but this would stop infinite loops from happening, and the data would not be discarded unless every single router connected to the current router have already been passed through.
This leads on to a second idea, a more ambitious one. When the datagram reaches its source, the header containing the tracked IP addresses is sent back to the source computer. The route of IPs, and the time taken to transfer the data, is stored somewhere on the computer, probably the RAM. The router then sends “dummy data” of one or two bits to the previous destination address, and attempts to find a more efficient route. Again, route details are sent back to the source and stored in the source computer.
When the client wants to send or request data to/from the same destination again, the computer scans its RAM for saved routes and chooses the most efficient/quickest route so far. The list of IP addresses and the order they come in are stored in the IP Header of the datagram so that each router knows where to pass the datagram.
In this way, the client’s internet speed increases the more they use their favourite websites. The computer would periodically keep checking for new, efficient routes and updating its database. When the client’s computer is turned off, the list of routes are transferred from RAM to the computer’s hard drive, and when the computer is started up again the list of routes are loaded up into the RAM. The routes need to be available in RAM, as reading a route from the hard drive would be too slow for modern internet applications.
Websites that the user hasn’t visited in over a month could have their routes deleted, to save on space and RAM usage. This should also aleviate some privacy concerns. Users could even “opt in” to having their routes uploaded to an international database. Their computer would then periodically download more efficient routes, as found by the community that have opted in to this database.
The end result, ideally, would be a faster internet for everyone, simply by adopting new protocols.